
1강
데이터 : 실제 값
정보 : 데이터를 기반으로 의미를 부여한 것
DB: 한 조직에 필요한 정보를 공용으로 사용할 수 있도록 논리적으로 데이터를 모으고 중복을 최소화하여 구조적으로 저장한 것.
특징
1. 실시간 접근성 2. 계속적인 변화 3. 동시 공유 4. 내용에 따른 참조
DBMS : DB에서 데이터 추출, 조작,정의,제어 등 할수있는 DB 관리 시스템
DBMS 사용 이점
1. 데이터 독립화 2. 데이터 중복 최소화, 데이터 무결성 보장 3. 데이터 보안 향상 4. 관리 편의성 향상
객체-관계형 데이터베이스
1. 사용자 정의 타입 지원
2. 참조(reference)타입 지원
3. 중첩 테이블 지원
4. 대단위 객체의 저장 및 추출 가능
5. 객체간의 상속관계 지원
SQL: 구조적 질의 언어, 검색 시 절차가 아닌 조건을 기술하여 작성
- 테이터 조회 , 조작하기 위해 사용하는 표준검색언어로 조건을 기술하여 작성

컬럼 별칭: SELECT 조회 결과인 RESULT SET의 컬럼명을 지정
1. 컬럼명 AS 별칭 : 띄어쓰기 없이(특수문자 X) / 2. 컬럼명 별칭
3. 컬럼명 AS "별칭" : 제한 없이 어떤 문자, 특수문자, 띄어쓰기 O / 4.컬럼명 "별칭" : 3) 방법에서 AS 생략
01 DML
SELECT :테이블에서 데이터를 조회
- DISTINCT : 중복값을 한 번만 표시 SELECT 문에 딱 한번만 작성. 컬럼명 가장 앞에 작성
- WHERE 절: 조건절로 검색할 컬럼의 조건을 설정하여 행 결정 (여러개 작성시 AND, OR)
- 논리연산자 : AND, OR, NOT
- LIKE : 특정 패턴이 일치하는 걸 조회 문자 패턴 :%(모든 값) _(아무글자,개수)
와일드 카드 _ 포함해서 검색하는 법 WHERE 컬럼명 LIKE '___$_%' ESCAPE '$';
- IN : 목록안에서 같은게 있으면 조회결과에 포함한다
- 연결 연산자: ||
- ORDER BY: 정렬/ 옆에 붙을 수 있는건 컬럼명, 별칭, 컬럼순서
ORDER BY 컬럼명 | 별칭 | 컬럼순서 정렬방식 [NULL FIRST|LAST]
오름 차순일 때 : NULLS LAST 기본값
내림 차순일 때 : NULLS FIRST 기본값
02 함수
- 함수 : 컬럼 값을 읽어서 계산한 결과 반환
적용 위치 : SELECT절, WHERE절, ORDER BY절, GROUP BY절, HAVING절
- 단일행 ,
그룹 함수 : 하나 이상의 행을 그룹으로 묶어 하나의 결과만을 반환하는 함수
-> 차이점 : RESULT SET (조회 결과의 집합)에서 단일행은 N개를 읽으면 N개 , 그룹함수는 N개 값을 읽어도 1개 값 반환
문자처리 함수
- LENGTH : 컬럼값, 문자열 길이 반환
- INSTR : 문자 시작위치부터 지정 순번까지 검색, 지정한 순번째로 검색되는 문자의 시작 위치를 반환 (마이너스는 뒤에서부터 검색)
- SUBSTR : 문자열 잘라서 반환
- TRIM : 앞,뒤, 양쪽 지정된 문자 제거
- LPAD|RPAD : 임이의 문자열 덧붙여 반환
- LOWER | UPPER | INITCAP : 소문자 | 대문자 | 맨 앞글자만 대문자
숫자처리함수
ABS(숫자|컬럼명) : 절대값
MOD : 나머지
ROUND : 반올림
CEIL(숫자|컬럼명): 올림
FLOOR(숫자|컬럼명): 내림
TRUNC : 지정한 위치부터의 자리의 수를 버리고(절삭) 반환
내림, 버림의 차이 -> 음수일 때 확인 가능 *유념!
SELECT FLOOR(-123.5), TRUNC(-123.5) FROM DUAL; - 124 - 123
날짜처리함수
SYSDATE 날짜(년, 월, 일, 시, 분, 초)를 반환하는 함수(현재시간)
LAST_DAY : 마지막 날짜
ADD_MONTHS :날짜에 더해진 수 만큼 개월을 추가하여 반환
EXTRACT : 날짜데이터에서 년,월,일 정보 추출
EXTRACT(YEAR | MONTH | DAY FROM 날짜)
형변환 함수 : CHAR(문자열), NUMBER(숫자), DATE(시간)끼리의 형변환
- TO_CHAR(숫자 [, 포맷]) : 숫자 데이터를 지정된 포맷의 문자열로 변경
AM|PM : 오전/오후 중 알맞은 것을 표시 /HH24: 시간(24시간) /HH : 시간(12시간) /MI : 분 /SS : 초
- TO_DATE('문자열' : 컬럼 [, 포맷] : 문자열을 날짜로 변환
연도 표기 R, Y의 차이점: Y : 현재 세기(21세기 == 2000년대) / R : 변환하는 숫자가 50 이상이면 이전 세기(1900) (R이 라운드약자)
- TO_NUMBER : 문자열을 숫자로 반환
SELECT TO_CHAR(1000000, 'L9999999') FROM DUAL;
-- 'L' : 현재 시스템상에 설정된 나라의 화폐 기호
--> 화폐 기호를 바꾸는 방법 : 1. 시스템의 설정 나라 변경, 2. L대신 화폐 기호를 직접작성
SELECT TO_CHAR(1000000, 'L9999') FROM DUAL;
--(주의사항) 포맷에 지정된 칸 수가 숫자보다 적을경우 '#'으로 추정된다 .
NULL처리 함수
NVL : 컬럼 값이 NULL일 경우 다른 값으로 변경
선택함수
CASE: 조건식과 같으면 결과 값 반환(조건은 범위 값 가능)
CASE
WHEN 조건식 THEN 결과값
WHEN 조건식 THEN 결과값
WHEN 조건식 THEN 결과값
ELSE 결과값
END
DECODE: 비교하고자 하는 값 또는 컬럼이 조건식과 같으면 결과 값 반환
DECODE( 계산식 | 컬럼명 , 조건1, 값1, 조건2, 값2, ...... , 아무 것도 아닐 경우의 값)
그룹 함수 (MAX , SUM, AVG..)
COUNT : RESULT SET에 포함되는 행의 개수를 반환
1) COUNT(*) : 조회되는 행 중 NULL값이 있으면 NULL 포함한 전체 행 개수를 반환
2) COUNT(컬럼명) : 특정 컬럼에서 NULL을 제외한 행의 개수를 반환
3) COUNT(DISTINCT 컬럼명) : 특정 컬럼에서 NULL + 중복을 제외한 행의 개수를 반환
03 GROUP BY HAVING
⭐ SELECT문 해석 순서 ⭐
5: SELECT 컬럼명 | 계산식 | 함수 AS 별칭
1: FROM 참조할 테이블명
2: WHERE 컬럼명 | 함수식 비교연산자 비교값
3: GROUP BY 그룹으로 묶을 컬럼명
4: HAVING 그룹함수식 비교연산자 비교값
6: ORDER BY 컬럼명 | 별칭 | 컬럼순서 [ASC|DESC] [NULLS FIRST | LAST];
GROUP BY : 그룹별로 하나의 결과값만 산출 , 같은 값들이 여러 개 기록된 컬럼을 가지고 같은 값들을 하위 그룹으로 묶는 방법
GROUP BY 컬럼명 | 함수식 [,컬럼명 | 함수식 .... ]
* GROUP BY가 포함된 SELECT절에 단일행, 그룹함수가 혼용된 경우
단일행 부분을 모두 GROUP BY절에 그대로 작성(그룹함수는 그대로 작성)
HAVING : 그룹함수끼리 나온걸 조건 설정할 때 사용
HAVING 컬럼명 | 그룹함수식 비교연산자 비교값 //WHERE에는 그룹함수X HAVING에는 가능
집계 함수: ROLLUP(그룹별로 중간 집계), CUBE( 산출 결과를 집계)
집합 연산자 :여러 SELECT의 결과를 하나의 RESULT SET으로 합치는 연산자
* 집합 연산에 사용되는 SELECT문의 SELECT절은 모두 동일해야 한다.
UNION 합집합 : 여러 SELECT문의 결과를 하나로
INTERSECT 교집합 : 공통된 부분만 조회
UNION ALL 합집합 + 교집합 : 여러 SELECT 결과를 하나로 합침(중복 영역도 모두 포함)
MINUS 차집합 : 중복되는 부분을 제거하여 조회
04 join
JOIN : 하나 이상의 테이블을 연결해 하나의 RESULT SET으로 조회
관계 맺는법 : 두 테이블에서 같은 데이터를 저장하는 컬럼이 연결고리
1) 내부 조인 : 연결되는 컬럼의 값이 일치하는 행들만 조인
컬럼명이 다른경우: ON()
컬럼명이 같을 경우: USING
2) 외부 조인 : 두 테이블의 지정하는 컬럼값이 일치하지 않는 행도 조인에 포함
LEFT [OUTER] JOIN , RIGHT [OUTER] JOIN, FULL [OUTER] JOIN
3) 교차 조인 - 조인 테이블의 각 행들이 모두 매핑된 데이터가 검색되는 방법(곱집합)
4) 비등가 조인 : 정한 컬럼 값이 일치하는 경우가 아닌, 값의 범위에 포함되는 행들을 연결
- 같을 때는 ON이 아니라 USING
5) 자체조인- 동일한 타입과 이름을 가진 컬럼이 있는 테이블 간의 조인
6) 다중조인- N개의 테이블을 조회할 때 사용
주의사항!! SELECT절 순서대로 JOIN 해야한다
05 subquery
서브쿼리 : 메인쿼리(기존쿼리)를 위해 보조 역할을 하는 쿼리문
*SELECT, FROM, WHERE, HAVGIN 절에서 사용가능
- 단일행 서브쿼리 : 서브쿼리의 조회 결과 값의 개수가 1개일 때
- 다중행 서브쿼리 : 서브쿼리의 조회 결과 값의 개수가 여러개일 때
IN / NOT IN : 여러 결과값 중 한 개라도 일치?
> ANY, < ANY : 여러 결과값 중 한개라도 큰 / 작은 경우, 가장 작은 값보다 큰가? / 가장 큰 값 보다 작은가?
> ALL, < ALL : 여러 결과값 모든 값보다 큰 / 작은 경우 / 가장 큰 값 보다 큰가? / 가장 작은 값 보다 작은가?
EXISTS / NOT EXISTS : 값이 존재하는가? / 존재하지 않는가?
- 상관쿼리 : 메인쿼리의 테이블값이 변경되면 서브쿼리의 결과값도 바뀌게 되는 구조 (메인쿼리 수행 후 서브쿼리 수행)
- 스칼라 서브쿼리 : SELECT절에 사용되는 서브쿼리 결과로 1행만 반환
어디서 쓰이면 인라인뷰
- 인라인 뷰: FROM 절에서 서브쿼리 사용
- WITH : 서브쿼리에 이름붙여주는 것
- RANK() OVER : 동일 순위 인원 수 건너뛰고 순위 계산 / DENSE_RANK() OVER : 동일 순위 이후 등수부터 순위 계산
06 DML
DML : 테이블에 값을 삽입(INSERT), 수정(UPDATE), 삭제(DELETE)하는데이터 조작 언어
INSERT : 테이블에 새로운 행을 추가
INSERT INTO 테이블명 VALUES(데이터, 데이터, ...)
INSERT INTO 테이블명(컬럼명, 컬럼명, 컬럼명,...) VALUES (데이터1, 데이터2, 데이터3, ...);
* 컬럼 제약조건에 NOT NULL이 있는데 INSERT에 NULL이 들어가면 오류
* INSERT시 VALUES 대신 서브쿼리 사용 가능
INSERT ALL : INSERT 시 서브쿼리가 사용하는 테이블이 같은 경우, 두 개 이상의 테이블에 INSERT ALL 구문을 이용하여 한 번에 삽입 가능
+조건) 조건절이 같아야 한다.
UPDATE : 테이블에 기록된 컬럼의 값을 수정하는 구문
UPDATE 테이블명 SET 컬럼명 = 바꿀값 [WHERE 컬럼명 비교연산자 비교값];
* UPDATE시에도 서브쿼리 사용 가능/ , 로 중복
* 다중행 다중열 서브쿼리를 이용한 UPDATE문
DELETE :테이블의 행을 삭제하는 구문
DELETE FROM 테이블명 WHERE 조건설정
만약 WHERE 조건을 설정하지 않으면 모든 행이 다 삭제됨
07 , 09 DDL
DDL : 객체(OBJECT)를 만들고(CREATE), 수정(ALTER), 삭제(DROP) 등 데이터의 전체 구조를 정의하는 언어
데이터 딕셔너리 : 자원을 효율적으로 관리하기 위한 다양한 정보를 저장하는 시스템 테이블, 데이터베이스 서버에 의해 자동으로 갱신되는 테이블
CREATE : 테이블이나 인덱스, 뷰 등 다양한 데이터베이스 객체를 생성하는 구문
테이블: 행과 열로 구성된 가장 기본적인 데이터베이스 객체로 데이터가 저장
테이블 생성법
CREATE TABLE 테이블명(
컬럼명 데이터타입 제약조건,
....
);
자료형 : 숫자, 문자(char varchar2) DATE
컬럼에 주석 달기
COMMENT ON COLUMN 테이블명.컬럼명 IS '주석내용';
제약 조건(CONSTRAINTS)
사용자가 원하는 조건의 데이터만 유지하기 위해서 특정 컬럼에 설정하는 제약으로 데이터 무결성 보장 목적
데이터 무결성 : 중복데이터 X 널 X = 저장 데이터의 정확성과 일관성)
NOT NULL : 컬럼 값 NULL 불가, 컬럼에 작성되는 데이터에 NULL이 작성되지 못하게 하는 제약
UNIQUE : 같은 컬럼 내 중복 값 불가
PRIMARY KEY : 테이블의 각 행을 구분하는 식별자 역할을 지정하는 제약조건 (NOT NULL + UNIQUE ), 테이블 당 1개만 존재
FOREIGN KEY : 참조된 부모 테이블의 컬럼의 값만 자식 테이블 컬럼의 값으로 사용하게 하는 제약 조건(+null) + fk에 의해서 관계가 형성된다.
CHECK : 컬럼에 기록 될 값에 조건 설정
CHECK (컬럼명 비교연산자 비교값)
주의 : 비교값은 리터럴만 사용할 수 있음, 변하는 값이나 함수 X
컬럼 레벨 : 컬럼명 자료형(크기) [CONSTRAINT 이름] REFERENCES 참조할 테이블명 [(참조할컬럼)] [삭제룰]
테이블 레벨 : [CONSTRAINT 이름] FOREIGN KEY (적용할컬럼명) REFERENCES 참조할테이블명 [(참조할컬럼)] [삭제룰]
* 테이블 생성 시 제약 조건 설정 가능 레벨

컬럼 레벨 + 테이블 레벨 : UNIQUE, PK, FK, CHECK
컬럼레벨만 가능 : NOT NULL
* FK 제약조건의 삭제 옵션
- ON DELETE SET NULL : 부모 삭제 시 자식 NULL로 변경
- ON DELETE CASCADE : 부모 삭제 시 자식 행 삭제
- TRUNCATE
테이블의 전체 행을 삭제 (DELETE보다 수행속도가 더 빠르다.)
ROLLBACK을 통해 복구 x
* 참조될 수 있는 컬럼은 PRIMARY KEY컬럼과, UNIQUE 지정된 컬럼만 외래키로 사용할 수 있음
참조할 테이블의 참조할 컬럼명이 생략이 되면, PRIMARY KEY로 설정된 컬럼이 자동 참조할 컬럼이 됨
FOREIGN KEY 삭제 옵션
- ON DELETE SET NULL : 삭제 옵션이 적용된 테이블 생성
- ON DELETE CASCADE : 부모키 삭제시 자식키도 함께 삭제
ALTER: 객체 수정 구문
1) 컬럼 추가(ADD (컬럼명 데이터타입))
2) 컬럼 수정(MODIFY) 데이터 타입, 기본값 수정 (MODIFY 컬럼명 데이터타입 )
2-1) 컬럼 DEFAULT 값 변경하기 : MODIFY 컬럼명 DEFAULT 기본값
2-2) 여러 컬럼 한 번에 수정 : , 없이 작성
3) 컬럼 삭제(DROP COLUMN (삭제할 컬럼명))
* 데이터가 기록 되어 있어도 삭제 O, 삭제된 컬럼 복구 X , 최소 한 개의 컬럼이 존재 필수(== 모든 컬럼 삭제 불가)
** 제약조건 설정된 컬럼 삭제 방법 : DROP CASCADE CONSTRAINTS
(FK 제약조건을 무시하고 컬럼을 삭제하는 옵션 )
--> FK 제약조건으로 인해 참조 당하고 있는 부모 테이블 컬럼 먼저 지우기
2.제약 조건 추가, 삭제
제약 조건 추가 : ADD CONSTRAINT 제약조건명 제약조건(컬럼명)
제약 조건 삭제 : DROP CONSTRAINT 제약조건명
3. 컬럼, 제약조건, 테이블 이름 변경
1) 컬럼 이름 변경(RENAME COLUMN 컬럼명 TO 변경명)
2) 제약조건 이름 변경(RENAME CONSTRAINT 제약조건명 TO 변경명)
3) 테이블명 변경(RENAME [테이블명] TO 변경명)
4. 테이블 삭제( DROP TABLE 테이블명 [CASCADE CONSTRAINTS];
참조 관계에서 부모테이블 삭제 시 발생하는 문제 및 해결
1) 자식 -> 부모 테이블 순서로 삭제하기
2) CASCADE CONSTRAINTS;
08 TCL
TCL : 트랜잭션 제어 언어
트랜잭션이란 데베의 논리적 연산 단위
- COMMIT : 메모리 버퍼에 저장된 데이터 변경 사항(INSERT, UPDATE, DELETE)을 DB에 실제로 반영
- ROLLBACK : 메모리 버퍼에 임시 저장된 데이터 변경 사항을 삭제하고 마지막 COMMIT 상태로 돌아간다.
- SAVEPOINT : 저장 지점을 정의, ROLLBACK 시 저장된 지점까지만 삭제
TCL 주의사항
1) TCL 구문은 DML(INSERT, UPDATE, DELETE )에만 적용된다.
2) DML 구문 작성 중 DDL 또는 DCL 구문이 수행될 경우 트랜잭션 내용이 바로 DB에 반영된다. (자동 COMMIT)
10 DCL
DCL : 데이터베이스 내의 객체에 대한 접근 권한 제어(부여, 회수)하는 언어
GRANT : 권한 부여 (GRANT 권한1, 권한2, ... TO 사용자 이름;)
REVOKE : 권환 회수, 취소
시스템 권한 : 사용자에게 시스템 권한을 부여할 때 사용

GRANT 권한1, 권한2, ...
TO 사용자 이름;
객체 권한 : 특정 객체 조작 권한 부여
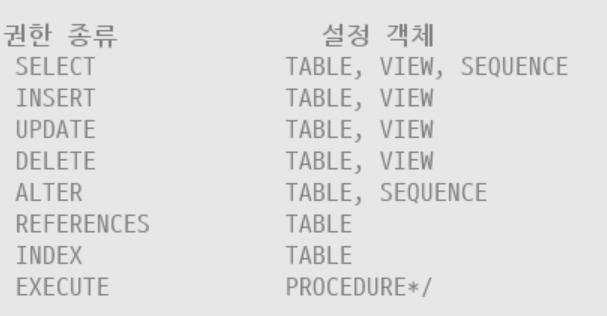
GRANT 권한 종류 [(컬럼명)] | ALL
ON 객체명 | ROLE 이름 | PUBLIC
TO 사용자 이름;
관리자 계정 : 데이터베이스의 생성과 관리를 담당하는 계정이며 모든 권한과 책임을 가지는 계정
사용자 계정 : 데이터베이스에 대하여 질의, 갱신 등의 작업 수행 가능한 계정으로 최소한의 권한만 가지는 계정
사용자 계정 생성
CREATE USER 사용자계정명 IDENTIFIED BY 비밀번호; => 사용자 계정 생성
GRANT CREATE SESSION TO 사용자계정명; => 데이터베이스 접속권한
GRANT CONNECT, RESOURCE TO testuser;
ROLE : 여러 가지 관련된 권한들을 묶어서 한번에 부여, 회수
1) CONNECT : 데이터베이스 접속 권한
2) RESOURCE : 데이터베이스를 사용하기 위한 기본 객체 생성 권한을 묶어둔 롤
11 VIEW / SEQUENCE /INDEX
VIEW: SELECT문의 실행 결과(RESULT SET)을 저장하는 객체, 논리적 가상 테이블
사용 목적
1) 복잡한 SELECT 문의 쉬운 재사용을 위해서
2) 테이블의 진짜 모습을 감출 수 있어 보안상 유리
VIEW 사용 시 주의 사항
1) ALTER 구문 사용 불가 : 가상이기 때문에 못한다.
2) VIEW를 이용한 DML(INSERT, UPDATE, DELETE)가 가능하지만 제약이 많아 보통 조회용도로만 사용
생성방법
CREATE OR REPLACE VIEW 뷰이름 AS 서브쿼리;
CREATE [OR REPLACE] [FORCE | NOFORCE] VIEW 뷰이름 [(alias[,alias]...]
AS subquery
[WITH CHECK OPTION]
[WITH READ ONLY];
OR REPLACE : 동일한 뷰 이름 존재하는 경우 덮어쓰고, 존재하지 않으면 새로 생성.
WITH READ ONLY : 뷰에 대해 조회만 가능( DML(INSERT,UPDATE,DELETE) ) 수행 불가)
* VIEW를 이용해 INSERT 진행시 원본 테이블에 삽입된다.
SEQUNCE : 순차적 번호 자동 발생기 역할의 객체 (고유키에 주로 사용)
SEQUENCE 사용 이유 : PRIMARY KEY(UNUQUE+ NOT NULL 특징) 컬럼에 사용될 값으로써 주로 사용
시퀀스 사용방법
CREATE SEQUENCE 시퀀스명
[STRAT WITH 숫자] -- 처음 발생시킬 시작값 지정, 생략하면 자동 1이 기본
[INCREMENT BY 숫자] -- 다음 값에 대한 증가치, 생략하면 자동 1이 기본
[MAXVALUE 숫자 | NOMAXVALUE] -- 발생시킬 최대값 지정 (10의 27승, -1)
[MINVALUE 숫자 | NOMINVALUE] -- 최소값 지정 (-10의 26승)
[CYCLE | NOCYCLE] -- 값 순환 여부 지정
[CACHE 바이트크기 | NOCACHE] -- 캐쉬메모리 기본값은 20바이트, 최소값은 2바이트
1) 시퀀스명.NEXTVAL : 다음 시퀀스 번호를 얻어온다.
2) 시퀀스명.CURRVAL : 현재 시퀀스 번호를 얻어온다.
* 시퀀스를 새로 만들고 NEXTVAL을 하지 않으면 현재값이 뭔지 모르니깐 CURRVAL 먼저 실행하면 오류가 발생한다!!
시퀀스 이름 변경
ALTER SEQUENCE 시퀀스명
*시작값(START WITH) 외에는 다 변경된다 --> 재설정 필요 시 기존 시퀀스 DROP후 재생성
INDEX
CREATE [UNIQUE] INDEX 인덱스명
ON 테이블명 (컬럼명, 컬럼명, ... | 함수명, 함수계산식);
SELECT의 처리 속도를 향상시키기 위해 컬럼에 대해 생성하는 객체 , 이진트리 구조로 정렬과 검색속도가 빠르다
인덱스는 데이터가 있어야한다.
인덱스 장점
- 이진트리 형식으로 구성되어 자동 정렬 및, 검색 속도가 빨라짐
- 시스템에 걸리는 부하를 줄여 시스템 전체 성능 향상
인덱스 단점
- 인덱스를 추가 하기위한 별도의 저장공간이 필요
- 인덱스를 생성하는데 시간이 걸림
- 데이터 변경작업(DML(INSERT/UPDATE/DELETE))이 빈번한 경우 오히려 성능 저하
12 PL/SQL
PL/SQL (Procedural Language extension to SQL)
- 오라클 자체에 내장되어있는 절차적 언어
- SQL 문장 내에서 변수의 정의, 조건처리(IF), 반복처리(LOOP, FOR, WHILE)등을 지원 SQL의 단점을 보완
구조
- 선언부(DECLARE SECTION) : DECLARE로 시작, 변수나 상수를 선언하는 부분
- 실행부(EXECUTABLE SECTION) : BEGIN으로 시작, 제어문, 반복문, 함수 정의등 로직 기술
- 예외처리부(EXCEOTION SECTIOIN) : EXCEPTION으로 시작, 예외사항 발생 시 해결하기 위한 문장 기술
장점
BLOCK 구조로 다수의 SQL문을 한번에 ORACLE DB로 보내 처리하므로 수행 속도 향상
- PL/SQL의 모든 요소는 하나 또는 두 개 이상의 블록으로 구성하여 모듈화 가능
- 단순, 복잡한 데이터 형태의 변수 및 데이블의 데이터 구조와 컬럼명의 준하여 동적으로 변수 선언 가능
- EXCEPTION 루틴을 이용하여 ORACLE SERVER ERROR 처리 가능
+ 사용자 정의 에러 선언 및 처리도 가능
*프로시저 사용 시 출력 내용 화면에 보여주는 환경변수 (기본값 OFF)
SET SERVEROUTPUT ON;
BEGIN
DBMS_OUTPUT.PUT_LINE (' ');
END;
/
END 뒤 '/' 기호는 PL/SQL 블록을 종결시킨다는 의미
타입 변수 : 오라클 데이터 타입의 변수
레퍼런스 변수 : 테이블 또는 뷰의 컬럼을 참조하여 지정하는 변수
%TYPE : 해당 컬럼의 데이터 타입을 얻음.(하나씩만 값을 저장할 수 있다)
%ROWTYPE : 한 행에 있는 모든 컬럼의 데이터 타입을 얻음.
선택문(조건문)
IF ~ THEN ~ END IF (단일 IF문)
IF ~ THEN ~ ELSE ~ END IF (IF ~ ESLE문)
IF ~ THEN ~ ELSIF ~ ELSE ~ END IF (IF ~ ESLE IF ~ ELSE문)
CASE ~ WHEN ~ THEN ~ END(SWITCH ~ CASE 문)
반복문 : 내부에 처리문을 작성하고 마지막에 LOOP를 벗어날 조건을 명시
1) BAISIC LOOP
LOOP
처리문
조건문
END LOOP;
2) FOR LOOP
FOR 인덱스 IN [REVERSE] 초기값..최종값
LOOP
처리문
END LOOP;
예외처리
EXCEPTION WHEN 예외명1 TEHN 예외처리구문1
WHEN 예외명2 THEN 예외처리구문2
...
WHEN OTHERS THEN 예외처리 구문N;
13 PROCEDURE / FUNCTION
Procedure(프로시져) : PL/SQL문 저장 객체
- 필요할 때마다 복잡한 구문을 다시 입력할 필요 없이 간단하게 호출해서 실행 결과를 얻을 수 있음
- 특정 로직을 처리하기만 하고 결과값을 반환하지 않음
FUNCTION : OUT 매개변수를 사용하지 않아도 실행 결과 O
Procedure와 Function 의 차이
-실행 후 반환값이 있을 수도, 없을 수도 있으면 PROCEDURE
- 실행 후 반환값이 있다면 FUNCTION
프로시져 생성 방법
CREATE OR REPLACE PROCEDURE 프로시저명
(매개변수명1 [IN | OUT | IN OUT] 데이터타입[:= DEFAULT값],
매개변수명2 [IN | OUT | IN OUT] 데이터타입[:= DEFAULT값],
...
)
IS
선언부
BEGIN
실행부
[EXCEPTION
예외처리부]
END [프로시저명];
/
프로시져 실행 방법
EXECUTE(OR EXEC) 프로시저명;
SET SERVEROUTPUT ON; -- 이걸 실행해야 된다.
프로시저 사용 시 출력하는 내용을 화면에 보여주도록 설정하는 환경변수
IN/OUT 매개변수 있는 프로시져
- IN 매개변수 : 프로시저 내부에서 사용될 변수
- OUT 매개변수 : 프로시저 외부(호출부)에서 사용될 변수
바인드 변수(VARIABLE or VAR 변수명 자료형(크기)) : SQL 문장을 실행할 때 SQL에 사용 값을 전달할 수 있는 통로 역할을 하는 변수
:변수명== 결과로 얻어온 값을 바인드 변수에 대입
-- 바인드 변수는 ':변수명' 형태로 참조 가능
FUNCTION
CREATE OR REPLACE FUNCTION 함수명(매개변수1 매개변수타입, ... )
RETURN 데이터타입
IS
선언부
BEGIN
실행부
RETURN 반환값; -- 프로시져랑 다르게 RETURN 구문이 추가됨
[EXCPTION
예외처리부]
END [함수명];
/
CURSOR(커서) : SELECT문 처리 결과(처리 결과가 여러 행(ROW))를 담고있는 메모리 공간에 대한 포인터
14 TRIGGER
TRIGGER(트리거) : 테이블이나 뷰가 DML문(INSERT, UPDATE, DELETE 등)에 의해 변경될 경우 자동으로 실행될 내용 정의하여 저장하는 객체(PROCEDURE)
트리거 생성
CREATE [OR REPLACE] TRIGGER 트리거명
BEFORE | AFTER
INSERT | UPDATE | DELETE
ON 테이블명
[FOR EACH ROW] -- ROW TRIGGER 옵션
[WHEN 조건]
DECLARE
-- 선언부
BEGIN
-- 실행부
[EXCEPTION]
END;
/
트리거 종류
SQL문의 실행 시기에 따른 분류
- BEFORE TRIGGER : SQL문 실행 전 트리거 실행
- AFTER TRIGGER : SQL문 실해 후 트리거 실행
SQL문의 의해 영향을 받는 각 ROW에 따른 분류
- ROW TRIGGER : SQL문 각 ROW에 대해 한번씩 실행
트리거 생성 시 FOR EACH ROW 옵션 작성
:OLD : 참조 전 열의 값(INSERT: 입력 전 자료, UPDATE : 수정 전 자료, DELETE : 삭제할 자료)
:NEW : 참조 후 열의 값(INSERT : 입력 할 자료, UPDATE : 수정 할 자료)
- STATMENT TRIGGER : SQL문에 대해 한번만 실행(DEFAULT TRIGGER)
'Backend > Oracle' 카테고리의 다른 글
| [SQL] 계층형 쿼리 (0) | 2022.01.19 |
|---|---|
| [DB] TRIGGER (0) | 2021.09.30 |
| [DB] PROCEDURE (0) | 2021.09.29 |
| [DB] PL/SQL , (타입,레퍼런스)변수, 조건문, CASE문, 반복문, FOR , 예외처리 (0) | 2021.09.29 |
| [DB] VIEW, SEQUENCE, INDEX (0) | 2021.09.29 |